Complexity class
In computational complexity theory, a complexity class is a set of problems of related resource-based complexity. A typical complexity class has a definition of the form:
- the set of problems that can be solved by an abstract machine M using O(f(n)) of resource R, where n is the size of the input.
For example, the class NP is the set of decision problems whose solutions can be verified by a non-deterministic Turing machine in polynomial time, while the class PSPACE is the set of decision problems that can be solved by a deterministic Turing machine in polynomial space.
The simpler complexity classes are defined by the following factors:
- The type of computational problem: The most commonly used problems are decision problems. However, complexity classes can be defined based on function problems (an example is FP), counting problems (e.g. #P), optimization problems, promise problems, etc.
- The model of computation: The most common model of computation is the deterministic Turing machine, but many complexity classes are based on nondeterministic Turing machines, boolean circuits, quantum Turing machines, monotone circuits, etc.
- The resource (or resources) that are being bounded and the bounds: These two properties are usually stated together, such as "polynomial time", "logarithmic space", "constant depth", etc.
Many complexity classes can be characterized in terms of the mathematical logic needed to express them; see descriptive complexity.
Bounding the computation time above by some concrete function f(n) often yields complexity classes that depend on the chosen machine model. For instance, the language {xx | x is any binary string} can be solved in linear time on a multi-tape Turing machine, but necessarily requires quadratic time in the model of single-tape Turing machines. If we allow polynomial variations in running time, Cobham-Edmonds thesis states that "the time complexities in any two reasonable and general models of computation are polynomially related" (Goldreich 2008, Chapter 1.2). This forms the basis for the complexity class P, which is the set of decision problems solvable by a deterministic Turing machine within polynomial time. The corresponding set of function problems is FP.
The Blum axioms can be used to define complexity classes without referring to a concrete computational model.
Important complexity classes
Many important complexity classes can be defined by bounding the time or space used by the algorithm. Some important complexity classes of decision problems defined in this manner are the following:
| Complexity class |
Model of computation |
Resource constraint |
| DTIME(f(n)) |
Deterministic Turing machine |
Time f(n) |
| P |
Deterministic Turing machine |
Time poly(n) |
| EXPTIME |
Deterministic Turing machine |
Time 2poly(n) |
| NTIME(f(n)) |
Non-deterministic Turing machine |
Time f(n) |
| NP |
Non-deterministic Turing machine |
Time poly(n) |
| NEXPTIME |
Non-deterministic Turing machine |
Time 2poly(n) |
| DSPACE(f(n)) |
Deterministic Turing machine |
Space f(n) |
| L |
Deterministic Turing machine |
Space O(log n) |
| PSPACE |
Deterministic Turing machine |
Space poly(n) |
| EXPSPACE |
Deterministic Turing machine |
Space 2poly(n) |
| NSPACE(f(n)) |
Non-deterministic Turing machine |
Space f(n) |
| NL |
Non-deterministic Turing machine |
Space O(log n) |
| NPSPACE |
Non-deterministic Turing machine |
Space poly(n) |
| NEXPSPACE |
Non-deterministic Turing machine |
Space 2poly(n) |
It turns out that PSPACE = NPSPACE and EXPSPACE = NEXPSPACE by Savitch's theorem.
Other important complexity classes include BPP, ZPP and RP, which are defined using probabilistic Turing machines; AC and NC, which are defined using boolean circuits and BQP and QMA, which are defined using quantum Turing machines. #P is an important complexity class of counting problems (not decision problems). Classes like IP and AM are defined using Interactive proof systems. ALL is the class of all decision problems.
Reduction
Many complexity classes are defined using the concept of a reduction. A reduction is a transformation of one problem into another problem. It captures the informal notion of a problem being at least as difficult as another problem. For instance, if a problem X can be solved using an algorithm for Y, X is no more difficult than Y, and we say that X reduces to Y. There are many different type of reductions, based on the method of reduction, such as Cook reductions, Karp reductions and Levin reductions, and the bound on the complexity of reductions, such as polynomial-time reductions or log-space reductions.
The most commonly used reduction is a polynomial-time reduction. This means that the reduction process takes polynomial time. For example, the problem of squaring an integer can be reduced to the problem of multiplying two integers. This means an algorithm for multiplying two integers can be used to square an integer. Indeed, this can be done by giving the same input to both inputs of the multiplication algorithm. Thus we see that squaring is not more difficult than multiplication, since squaring can be reduced to multiplication.
This motivates the concept of a problem being hard for a complexity class. A problem X is hard for a class of problems C if every problem in C can be reduced to X. Thus no problem in C is harder than X, since an algorithm for X allows us to solve any problem in C. Of course, the notion of hard problems depends on the type of reduction being used. For complexity classes larger than P, polynomial-time reductions are commonly used. In particular, the set of problems that are hard for NP is the set of NP-hard problems.
If a problem X is in C and hard for C, then X is said to be complete for C. This means that X is the hardest problem in C (Since there could be many problems which are equally hard, one might say that X is one of the hardest problems in C). Thus the class of NP-complete problems contains the most difficult problems in NP, in the sense that they are the ones most likely not to be in P. Because the problem P = NP is not solved, being able to reduce another problem, Π1, to a known NP-complete problem, Π2, would indicate that there is no known polynomial-time solution for Π1. This is because a polynomial-time solution to Π1 would yield a polynomial-time solution to Π2. Similarly, because all NP problems can be reduced to the set, finding an NP-complete problem that can be solved in polynomial time would mean that P = NP.
Closure properties of classes
Complexity classes have a variety of closure properties; for example, decision classes may be closed under negation, disjunction, conjunction, or even under all Boolean operations. Moreover, they might also be closed under a variety of quantification schemes. P, for instance, is closed under all Boolean operations, and under quantification over polynomially sized domains. However, it is most likely not closed under quantification over exponential sized domains.
Each class X which is not closed under negation has a complement class Co-Y, which consists of the complements of the languages contained in X. Similarly one can define the Boolean closure of a class, and so on; this is however less commonly done.
One possible route to separating two complexity classes is to find some closure property possessed by one and not by the other.
Relationships between complexity classes
The following table shows some of the classes of problems (or languages, or grammars) that are considered in complexity theory. If class X is a strict subset of Y, then X is shown below Y, with a dark line connecting them. If X is a subset, but it is unknown whether they are equal sets, then the line is lighter and is dotted. Technically, the breakdown into decidable and undecidable pertains more to the study of computability theory but is useful for putting the complexity classes in perspective.
Hierarchy theorems
For the complexity classes defined in this way, it is desirable to prove that relaxing the requirements on (say) computation time indeed defines a bigger set of problems. In particular, although DTIME(n) is contained in DTIME(n2), it would be interesting to know if the inclusion is strict. For time and space requirements, the answer to such questions is given by the time and space hierarchy theorems respectively. They are called hierarchy theorems because they induce a proper hierarchy on the classes defined by constraining the respective resources. Thus there are pairs of complexity classes such that one is properly included in the other. Having deduced such proper set inclusions, we can proceed to make quantitative statements about how much more additional time or space is needed in order to increase the number of problems that can be solved.
More precisely, the time hierarchy theorem states that
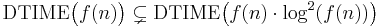 .
.
The space hierarchy theorem states that
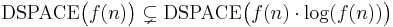 .
.
The time and space hierarchy theorems form the basis for most separation results of complexity classes. For instance, the time hierarchy theorem tells us that P is strictly contained in EXPTIME, and the space hierarchy theorem tells us that L is strictly contained in PSPACE.
See also
References
Further reading
- The Complexity Zoo: A huge list of complexity classes, as reference for experts.
- Diagram by Neil Immerman showing the hierarchy of complexity classes and how they fit together.
- Michael Garey, and David S. Johnson: Computers and Intractability: A Guide to the Theory of NP-Completeness. New York: W. H. Freeman & Co., 1979. The standard reference on NP-Complete problems - an important category of problems whose solutions appear to require an impractically long time to compute.
Important complexity classes ( more) |
|
| Classes considered feasible |
|
|
| Classes suspected to be infeasible |
|
|
| Classes considered infeasible |
|
|
| Class hierarchies |
|
|
| Families of complexity classes |
|
|